
現在、AWSのサービスを活用してタスク管理アプリの開発および運用を行っています。
データの取得は、API Gateway×Lambdaのいたってオーソドックスなアーキテクチャで実装しています。
これまで2年近くにわたりサービスを運用してましたが、最近になり、以下のようなLambdaエラーに遭遇しました。
LAMBDA_RUNTIME Failed to post handler success response. Http response code: 413.このエラーにより、API Gateway経由でフロントエンドにデータを渡すことができず、フロントエンド側でも画面描画のエラーが発生していました。
今回は、このエラーの原因と対策について説明します。
なお、対策は既存のアプリケーションに大きな影響を与えないことを前提としているため、必ずしも最適な方法ではないかもしれません。ご了承ください。
Lambdaレスポンス上限6MBエラーの概要と原因
今回、Lambdaで発生しているエラーは以下の通りです。
LAMBDA_RUNTIME Failed to post handler success response. Http response code: 413.また、このエラーが発生するLambda関数を実行しているAPI Gatewayもフロントエンドに502エラーを返しています。
エラーの原因は、Lambdaのレスポンス上限によるものです。 LambdaはAPI Gatewayなどのリクエスト単位でレスポンスの上限が6MBとなっています。
Lambdaには他にも実行時間や一時ファイル、コード、メモリの上限など様々な制限があります。
WEBアプリケーションのAPI経由のLambda関数でレスポンスが6MBを超える場合、Lambda関数の基本的な制約つぃて制限されてしまいます。
ただ、API Gatway経由でフロントに処理を返すものとして、レスポンスがそもそも6MBを超えるというは、API設計がよくないのではないかということは言うまでもないです。
Lambdaレスポンス上限エラーへの具体的な対策
原因は、Lambda関数のレスポンスが大きすぎることということがわかりました。
したがって、考えられる対策は以下の二つです。
- Lambda関数のレスポンスを6MB以下に減らす
- 6MB越えのレスポンスがあってもデータ取得できるように他サービスを組み合わせる
レスポンスサイズを6MB以下に圧縮する方法
対策を二つ挙げた時点で、まず最初に考えるべきは6MB以下への圧縮です。
特に、WEBアプリケーションで利用しているため、レスポンスが大きいということは処理に時間がかかっていることを意味し、ユーザー体験も良くありません。
例えば、今回のアプリでは、部門レベルで管理するタスクを一括取得していました。 一括でタスクを取得するAPI設計だったため、運用中にタスクが増加し、6MBの制限を超えてしまいました。
ここでAPI設計を見直し、完了タスクは別のAPIで取得するなどの方法も考えられます。
また、DBからデータを取得する際に、不要な全項目取得や意識しないjoin句などを見直し、データ量を絞ることも対策になります。
6MB制限を回避するための実際の方策
次の対策としては、たとえLambda関数のレスポンスが6MBを超えても他のサービスを併用してエラーなくフロントエンドにデータを渡す方法が検討されます。
実際に、今回はこちらの解決策を採用しました。
理由としては、API設計の見直しも考えましたが、運用中のアプリケーションであったため、フロントエンドのロジックも含め大きな改修が必要になる点を考慮したためです。
LambdaレスポンスをS3経由で取得する対策と実装
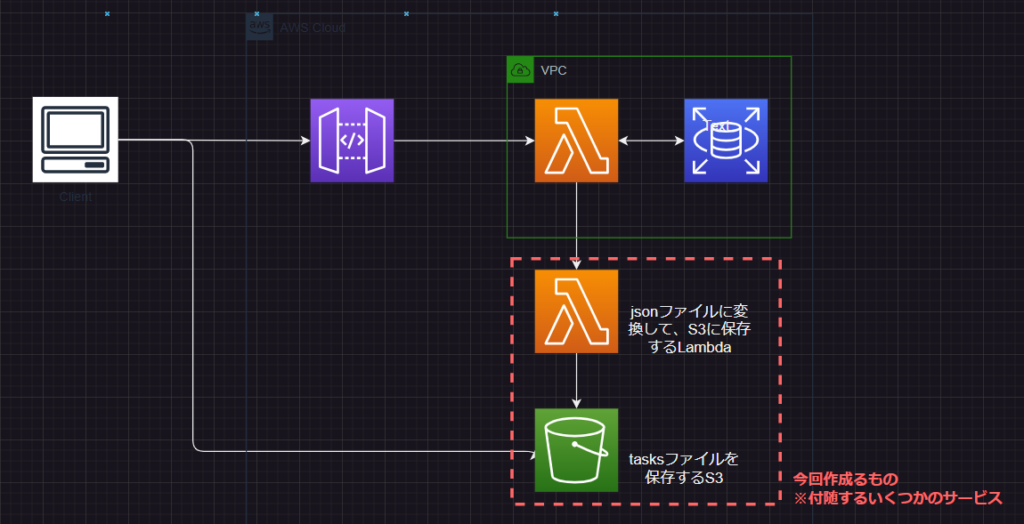
ここからは、実際の解決策をアーキテクチャ、コードを踏まえて紹介してきます。
具体的な対策として、Lambda関数のレスポンスをS3に保存し、フロントエンドからS3経由でデータを取得する方法を採用しました。
既存のAPI Gateway、Lambda、RDSはそのままとし、既存にはなるべく影響を与えない対策とします。
新たな対応として、これまで直接フロントに返していLambdaのレスポンスはS3に保存するように対応します。
API Gateway経由でフロントエンドに渡すレスポンスはS3の署名付きURLとし、クライアントから直接S3にアクセスしてJSONファイルをダウンロードし、画面描画は従来通りに行います。
S3バケットとアップロード用Lambdaの作成
S3バケットを新たに作成し、レスポンスとして返していたJSONを引数として受け取り、JSONファイルに変換してS3に保存するLambda関数を作成します。リソースの作成はServerless Frameworkを使用しました。
serverless create --template aws-nodejs --path s3-tasks-bucket
cd s3-tasks-bucketS3バケットを作成するServerless.ymlの設定は次の通りです。
一時的な保存バケットであるため、ライフサイクルを設定していることと、CROSの設定を付与してアクセスできるようにしてます。
service: s3-tasks-bucket
frameworkVersion: "3"
provider:
name: aws
runtime: nodejs18.x
region: ap-northeast-1
versionFunction: false
logRetentionInDays: 1
iamRoleStatements:
- Effect: Allow
Action:
- s3:PutObject
- s3:GetObject
- s3:DeleteObject
Resource: arn:aws:s3:::${self:service}/*
- Effect: Allow
Action:
- s3:ListBucket
Resource: arn:aws:s3:::${self:service}
custom:
defaultStage: dev
resources:
Resources:
MyS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: ${self:service}
# ライフサイクル設定(有効期限1日)
LifecycleConfiguration:
Rules:
- Status: Enabled
ExpirationInDays: 1
AbortIncompleteMultipartUpload:
DaysAfterInitiation: 1
# CORSの設定
CorsConfiguration:
CorsRules:
- AllowedOrigins:
- "*"
AllowedMethods:
- GET
AllowedHeaders:
- "*"
MaxAge: 3000
JSONファイル化してS3に保存するLambda
次に、他のLambdaからresponseを受け取り、JSONファイル化してS3に保存するLambda関数を作成します。このLambda関数は、既存のLambda関数からInvokeとして呼び出される前提で作っていきます。
import json
import boto3
import base64
import os
import ulid
s3 = boto3.client('s3')
BUCKET_NAME = os.environ.get('BUCKET_NAME', 's3-tasks-bucket')
def handler(event, context):
try:
file_id = str(ulid.new())
file_name = f"tasks-{file_id}.json"
# eventに直接、json.dumps(response)を受け取る
file_content = json.dumps(event, indent=4)
# ファイルをアップロード
s3.put_object(Bucket=BUCKET_NAME, Key=file_name, Body=file_content,)
# 署名付きURLの発行
presigned_url = s3.generate_presigned_url(
'get_object',
Params={'Bucket': BUCKET_NAME, 'Key': file_name},
ExpiresIn=300 # 5min
)
return {
'statusCode': 200,
'body': json.dumps({'message': 'file uploaded successfully!', 'fileName': file_name, 'presignedUrl': presigned_url})
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps({'message': 'Failed to save result to S3', 'error': str(e)})
}
既存Lambda関数への組み込み
既存API Lambdaの追加変更は、なるべくシンプルなものとしました。以下は一部抜粋したコードです。
def json_serial(obj):
if isinstance(obj, (datetime, date)):
return obj.isoformat()
raise TypeError ("Type %s not serializable" % type(obj))
@logger.inject_lambda_context()
def handler(event, context=LambdaContext):
## ----略----
## RDSからTodoタスクを取得しています。
tasks = {
"before":[],
"working":[],
"done":[]
}
print(json.dumps(tasks, default=json_serial))
return {
'statusCode': 200,
'headers': {
"Access-Control-Allow-Origin": "*"
},
'body': json.dumps(presigned_url_response, default=json_serial)
}
修正後のコードは以下の通りです。
これまで、returnでフロントに返していたTasksを引数として、先ほど作成したS3に保存、署名付きURLを返すInvoke用のLambda関数を実行します。
def json_serial(obj):
if isinstance(obj, (datetime, date)):
return obj.isoformat()
raise TypeError ("Type %s not serializable" % type(obj))
def invoke_response_export_lambda(response): # 今回追加した関数
lambda_arn = os.environ['RESPONSE_EXPORT_AND_UPLOAD_S3_PRESIGNED_URL_ARN']
# responseをJSONに変換
payload = json.dumps(response, default=json_serial)
# Lambda関数をinvoke
response = boto3.client('lambda').invoke(
FunctionName=lambda_arn,
InvocationType='RequestResponse',
Payload=payload
)
# 結果を取得
response_payload = json.loads(response['Payload'].read())
# 結果を返す
if response_payload.get('statusCode') == 200:
presigned_url = json.loads(response_payload['body']).get('presignedUrl')
return {
'statusCode': 200,
'presignedUrl': presigned_url
}
else:
return {
'statusCode': response_payload.get('statusCode', 500),
'message': 'Failed to get presigned URL'
}
@logger.inject_lambda_context()
def handler(event, context=LambdaContext):
tasks = {
"before":[],
"working":[],
"done":[]
}
print(json.dumps(tasks, default=json_serial))
## tasksを引数に入れ、presignedURLを返す関数を実行
presigned_url_response = invoke_response_export_lambda(tasks)
print('Presigned URL: ', presigned_url_response)
if presigned_url_response.get('statusCode') == 200:
presigned_url = presigned_url_response.get('presignedUrl')
return {
'statusCode': 200,
'headers': {
"Access-Control-Allow-Origin": "*"
},
'body': json.dumps({'presignedUrl': presigned_url}, default=json_serial)
}
else:
return {
'statusCode': 500,
'headers': {
"Access-Control-Allow-Origin": "*"
},
'body': json.dumps({'message': 'Failed to get presigned URL'}, default=json_serial)
}
このように、タスクを取得するLambda関数はいくつかあるので、使いまわしできる構成とし、既存コードに単に追加するだけで済むようにしました。
フロント側からの処理の追加
最後に、フロントエンドからのデータ取得をS3の署名付きURL経由で行うように修正します。
なお、フロントエンドは、Vue.JSで構築しています。
const getTasksFromS3PresignedUrl = async (url, signal) => {
try {
console.log('URL', url);
const response = await fetch(url, { signal });
if (!response.ok) {
throw new Error('Network response was not ok');
}
const jsonData = await response.json();
return jsonData;
} catch (error) {
console.error('Failed to fetch tasks from S3 presigned URL:', error);
}
};
response = await API.GetAllTasks(params, signal).then((res) => {
return getTasksFromS3PresignedUrl(res.presignedUrl, signal);
});
既存のコードでAPIにアクセスして、レスポンスをstore管理することまでは実装してました。
今回の修正では、上記の処理に.then()で処理をつなげて、URLからファイルを取得する処理を追加しています。
フロントエンドの処理も既存のコードに極力影響を与えないことを念頭に置いて対策しています。
実装の上での注意点と考慮事項
今回紹介したコード抜粋、また対応自体はいくつか考慮すべき点が説明を省略していたり、対応をあえてしてないというものもあるので、実際に利用する上では、以下の点を必要に応じて考慮お願いします。
- 説明不足ポイント 既存のAPI LambdaはRDSに接続するため、VPC Lambdaとなっています。
今回新規作成したS3に保存するInvoke用のlambda関数はVPC外であるため、接続には、VPC Endpointが必要です。
今回作成したS3バケットとlambda関数は、別のスタックで構築しています。 lambda関数にはS3バケット名を環境変数として登録しています。先にS3用のスタックをdeployしてから、lambda側の設定に環境変数を設定し、lambda(+API Gatway)用のスタックをdeployする必要があります。 - 環境によって留意する点 今回は、フロントエンドから署名付きURLに直接アクセスしています。
署名付きURL自体は、有効期限を5分と比較的短い時間を設定していること、HTTPS通信していること、アプリユーザーが直接的には確認できないことなどの理由から、アプリ認証などの設定は追加していません。 必要に応じて、署名付きURLの流出を防ぐ処理は、対応を追加してください。
参考
以下の記事、ブログを参考にしています。

おわりに

これまで、なかなか目にする機会がなかったlambda関数のレスポンス上限6MBに対するエラーを回避しました。
すでにアプリ運用してから2年近くとなり、既存にはなるべく影響を与えないことを一番に考えたので、エラーを回避することかつ、よりシンプルに実装することが出来満足です。
ただし、実際にはデメリットとして、そもそもレスポンスが6MBあることで、処理時間が長くUXが悪かったものが、処理を追加したことでさらに悪化することになっています。
tasksを取得するロジックを根本的に見直して、UX向上につなげることが今後の課題として残っています。
ただ、新たな機能もまだまだリリースしたいものがあるので、新機能かリファクタリングか毎回悩まされます。。。。

コメント