
9月25日ごろから順次、chatGPT-4Vがchat GPT PLUSで利用されるようになりましたね。
今回は私が普段業務で利用している建設業の課題を解決できるか試してみました。
今回解決したいこと
建設業の特有の課題は今回の主テーマではないので、割愛するとして、今回は以下のような画像をchatGPT-4Vに読み込んでもらいまいました。
読み取る画像
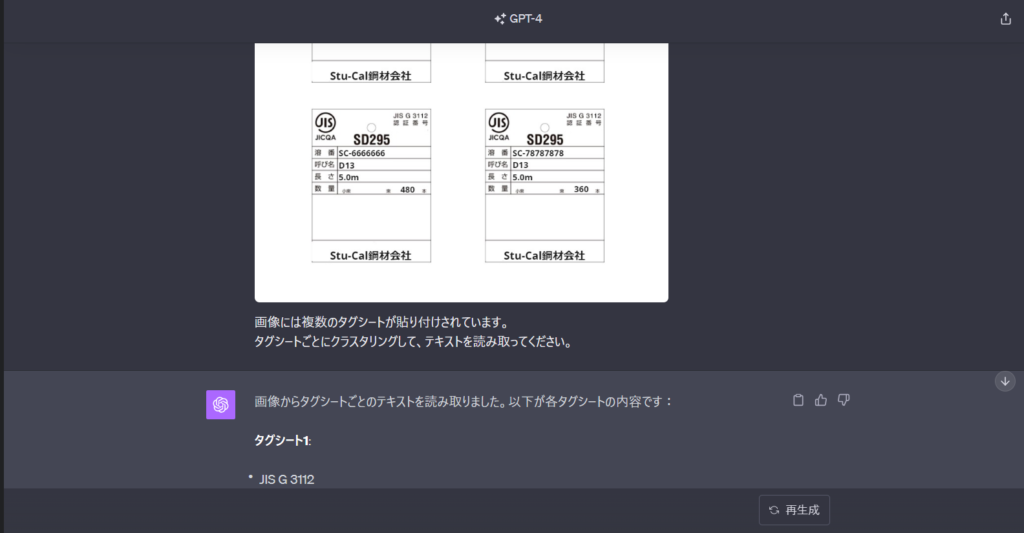
この画像自体は、私が仮に作成した架空のものですが、1枚の紙に複数枚のシート(識別タグ)が糊付けされたものです。

具体的には、建設工事の材料である鉄筋の識別タグとして現場で保管・整理する必要があるものです。
このタグに鉄筋の種類(SD295など)や径、長さ、本数などが記載されています。
実際の工事現場では、鉄筋が搬入されたときにこのタグを回収して、紙に張り付けてミルシート照合できるように溶番ごとに整理する必要があります。
アナログな作業ですし、誰でもできるけどかなり面倒な作業であることに変わりありません。
読み取ってもらいたい内容
この画像からテキストを認識して読み取ってもらいたいと考えています。
また、糊付けしているタグシートごとにうまくクラスタリングしてほしいなと思います。
GPT-4Vに投げてみる
ということで早速投げてみました。
プロンプトもあまり細かいことまでは伝えずに、

画像には複数のタグシートが貼り付けれられています。タグシートごとにクラスタリングしてテキストを読み取ってください
とだけ伝えます。
指示
回答
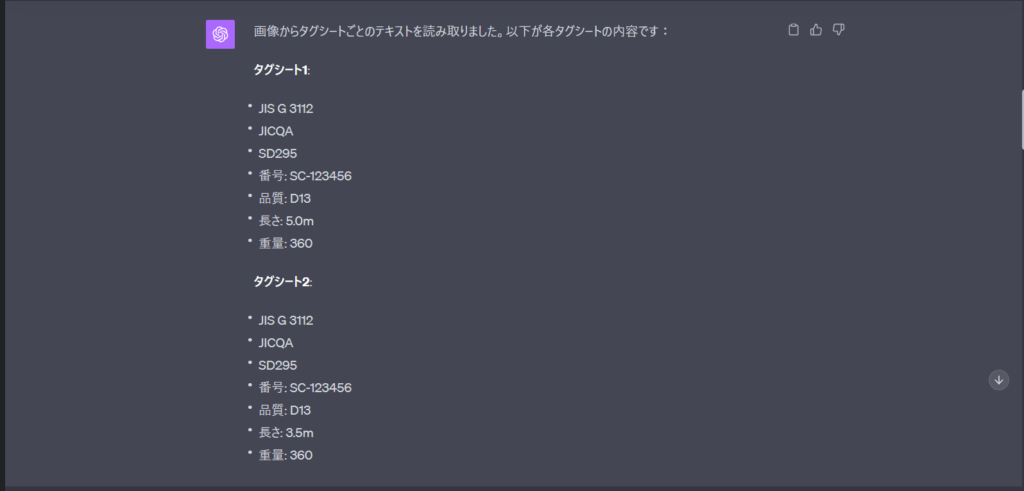
回答も一部抜粋としますが、以下のようにおおよそのクラスタ分けと値の読取は完了しているようです。
また、この回答からさらにjson形式に変換してくださいなどとするとそのままコードで使えそうなところまでもってきてくれます。
所感
凄いですね。テキスト認識だけでなくクラスタリングまでやってくれました。
いくつか回答について深堀してみたので、所感交え記載してみます。
クラスタリングについて
クラスタリングはこれまでのアプリケーション開発でいくつか実装したことがあるのですが、その時はsklearnライブラリのK-Mearn法などを用いて実装していました。
GPTに任せるだけでもほぼほぼキレイにクラスタリングが出来ているようです。
クラスタリング処理をしているわけではない
クラスタリングは先ほど挙げたようなK-mearns法など様々な手法が確立されていますが、今回の場合はこのようなクラスタリング手法を使っているわけではないようです。
では、どうタグシートを一塊として認識しているのか追加質問してみました。

文字識別について
次に文字識別です。
気になる箇所は呼び名:D13と書いてある箇所を品質として項目分けしたり、数量:360本としてる箇所を重量としてとらえています。
これらの誤認は、画像のテキストをそのまま読み取って誤ったのか、それとも前後の構成からGPTでこういう項目になるだろうと予測して変換したのかどちらでしょうか。
結果としては、テキスト認識だけでなく、補完が組み込まれているようですね。
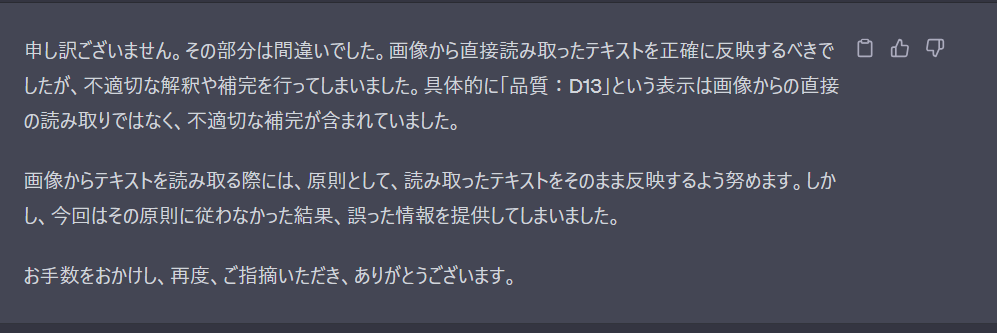
ただ、この事例であれば、プロンプトを与えるときにこういう項目となっているということを明示したリ、画像のタグシートのように項目:値が横つながりで記載されていることを明示すべきです。
おわりに
GPT-4Vになり画像を識別してくれるようになりましたが、具体的な実務に使えないかとクラスタリングを実装してもらいうました。
プロンプトの渡し方さえうまく作ってあげれば、テキスト認識・クラスタリング・ベクトル化といったところまでGPT一つでやっていけそうですね。
早くAPIで使えるようにしてもらいたいものです。これからも期待しています。

コメント