
今は、私が所属する建設専門の仕様・法律さらに社内規定などをRAGにより学習させたLLMアプリケーションの開発に余念がないです。
基本的には、AWSサービスとLangChain、さらにもmomentoを使用して作成することが多いです。
また、現在開発しているLLMアプリは、LangChainを利用しているLambdaから他アカウントのKendraサービスを利用してLLM回答用の参照ドキュメントとして用いています。
Kendraは如何せん高価なので、Kendra用アカウントを作成して、そこでコスト管理することためです。
Kendraアカウント内でLLMアプリ作っていってもいいのですが、それではコスト管理しているメリットがなくなってしまします。
そこで、メインアカウントのLambda(LangChain)から他アカウントのKendraサービスにLangChainのクラス経由で接続してみました。
私は、LangChain触りだしたものこの書籍がきっかけです。
本当に神!! ただ、情報が日々更新されるようなジャンルなので、なるべく早くこの書籍は試してほしいです。そして、自身の目的とするアプリや開発環境にて開発していきましょう!!

開発環境とアーキテクチャ
開発環境は、LangChainがさまざまなライブラリを統括したようなフレームワークであることから、基本的には最新版をインストールするのでしょうが、ちょこちょこ必要な変数などが変わっていくので、参考までに記載しておきます。
AWS CDK:2.105.0 [言語: Python]
Lambda:ランタイムPython3.10
LangChain:0.0.339
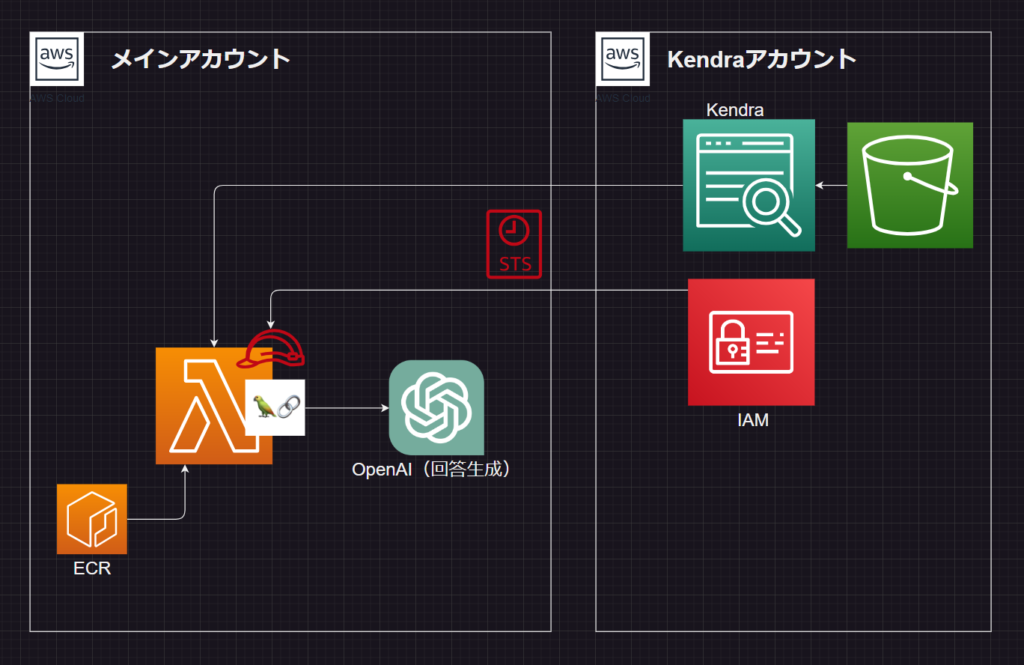
アーキテクチャ図は、このようになっています。
メインアカウントであるLambda作成の箇所はAWS CDKで構築しており、Kendraアカウントの方は、コンソールからIAMロールの作成やKendraインデックスの作成は行っています。
なお、実際はユーザー(クライアント)からの接続や会話履歴保存のDBなども作成しておりますが、該当箇所のみの掲載としています。
Kendraアカウントでの準備
まずは、Kendraアカウントでのインデックスの準備とIAMロールの設定を行っています。
IAMロールの作成
他のAWSアカウントからの接続を許可するためにKendra側アカウントでIAMロールを作成します。
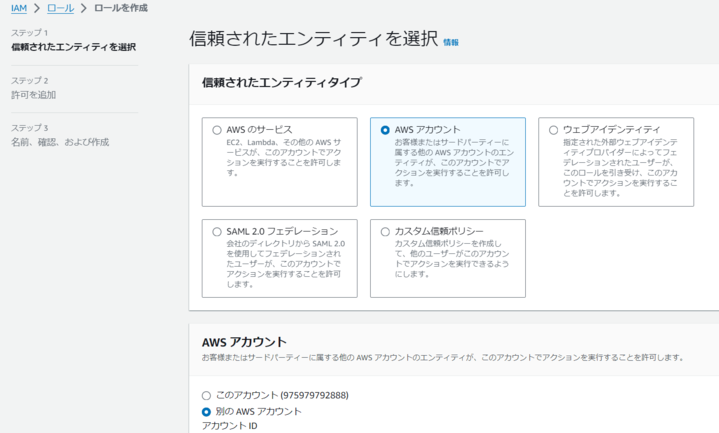
IAMロールの作成から「信頼されたエンティティタイプ」から「AWSアカウント」を選択し、「別のAWSアカウント」にチェックを入れ、メインアカウントのAWSアカウントIDを記載します。
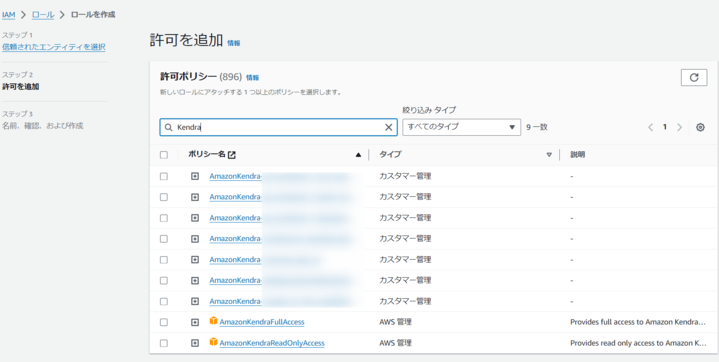
次に、アクセスの許可として、Kendraのフルアクセス権限を付与しました。
※実際は、Read権限だけあればよいのかもしれません。
最後に、信頼ポリシーとして、メインアカウントのLambdaをPricinpalとして指定しておきます。
まだLambda未作成の場合は、Lambda作成後にPricinpalの設定をして更新してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:sts::{{ メインAWSアカウントID }}:assumed-role/{{ lambda-function-name }}"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}
なお、スイッチロール自体の設定自体は、一般的なものと変わりないので詳細な設定方法などは他サイトを参考にしてください。

Kendraインデックスの作成
Kendraインデックスの作成は、ステップを割愛します。
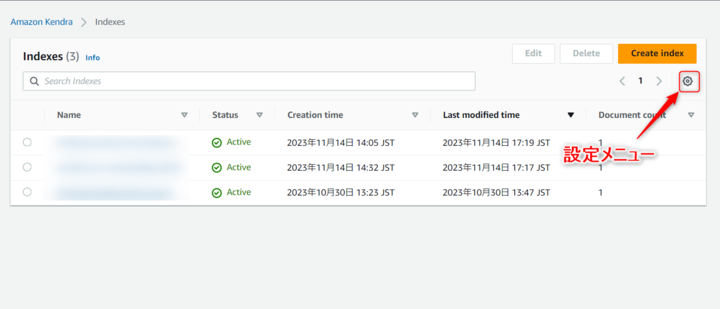
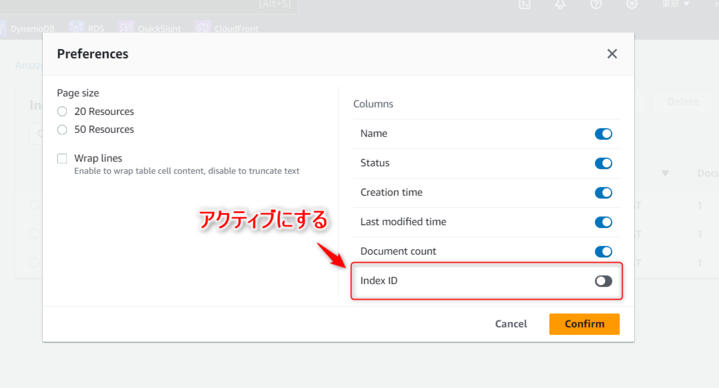
KendaraのInedexIDはLambdaで使用しますので、コピーしておいてください。
なお、Index IDは、Kendraのコンソールからインデックスを選択することで確認することもできますが、一覧画面から設定メニュー開き表示設定からアクティブとすることで確認も可能です。
AWS CDKによるLambda定義
次にメインアカウントに移り、AWS CDKで必要なLambdaを作成していきます。
AWS CDKは、LLMアプリケーションのメインがPythonで作成されているので、今回はPythonで構築していきます。 Node.jsでの構築の方が慣れているのですが・・・
スタック定義の概要
まずは、今回のLambdaですがLangChainのパッケージがが大きく、そのままでは250MBの制限に引っかかるので、ECRリポジトリにDocker経由でイメージを作成するものとしています。
必要なライブラリとして、LangChainやboto3など各種含めています。
次に、lamdaロールの設定で、Kendraサービスへのアクセス許可とKendraアカウントのロールへのスイッチロール許可を付与しています。
最後にLabmda関数の定義ですが、Kendraアカウントで作成したIAMロールがコードの中で必要になるので、環境変数として設定しています。
また、ECRイメージ経由で作成するため、コードの定義などがフォルダパスを指定するのではなく、設定しているECRリポジトリlambda_ecr_repository経由となるように設定しています。
スタック定義コード
from aws_cdk import (
Duration,
Size,
Stack,
aws_ecr as ecr,
aws_lambda as _lambda,
aws_iam as iam,
aws_logs as logs,
)
from constructs import Construct
import os
from dotenv import load_dotenv
load_dotenv()
class LangchainAiAgentStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# LambdaイメージのECRリポジトリ
## langchainのパッケージが大きいためimage経由とします。
lambda_ecr_repository = ecr.Repository.from_repository_name(
self, 'kendra-sts-lambda-image-ecr-repository',
'{{ ##ecr-name }}'
)
# lambda_Roleの設定
lambda_role = iam.Role(
self, 'kendra-sts-lambda-role',
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
inline_policies={
"lambda_policy": iam.PolicyDocument(
statements=[iam.PolicyStatement(
actions=[
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"lambda:InvokeFunction",
"kendra:*",
],
resources=["*"],
)]
),
## kendraアカウントを使用するためのクロスアカウントポリシー
"kendra_account_access_policy": iam.PolicyDocument(
statements=[iam.PolicyStatement(
actions=[
"sts:AssumeRole"
],
resources=["{{ kendraアカウント作成したIAM RoleのARN }}"],
)]
)
}
)
# lambda関数の定義
lambda_function = _lambda.Function(
self, 'kendra-sts-lambda-function',
code=_lambda.Code.from_ecr_image(
lambda_ecr_repository,
tag='latest'
),
handler=_lambda.Handler.FROM_IMAGE,
runtime=_lambda.Runtime.FROM_IMAGE,
role=lambda_role,
## kendaraアカウントで作成したロールARNを環境変数に設定。※envファイル推奨
environment={
"ROLE_ARN": "{{ kendraアカウント作成したIAM RoleのARN }}",
},
memory_size=1024,
timeout=Duration.minutes(5),
)Lambda(LangChain)経由でKendra接続
最後にLambda関数のコードの紹介です。
LangChainからLLMアプリを作成するところは割愛するとして、RAG手法を用いる参照ドキュメントにおいてKendraサービスを利用しています。
参照ドキュメントはretrieverとして設定できますが、ここで一時的なセッションを付与して、Kendraアカウントのロールを付与しています。
Kendaraサービスの利用は、LangChainから接続することが可能なので、ここでclientプロパティを設定することで、他アカウントのKendraサービスを参照しています。
なお、会話履歴の保持なども実際のアプリでは組み込んでいます。 会話履歴を考慮しないこともできますが、その場合は、利用するモデルがConversationalRetrievalChainではなく、RetrievalQAになるかと思います。
会話履歴を保持しない場合の設定に確証が持てなかったので、現在構成のまま記載しました。
ここではmoentoCacheというサービスを利用しているのですが、こちらも詳細説明は割愛します。
このLambda関数で紹介しているのは、あくまで他アカウントのKendaraサービスにLangChainから接続することなので、実際にはご自身のコードにあわせて修正していただければと思います。
import json
import boto3
import os
import hashlib
import logging
from datetime import timedelta
from dotenv import load_dotenv
from momento import (
CacheClient,
Configurations,
CredentialProvider,
PreviewVectorIndexClient,
)
from langchain.chat_models import ChatOpenAI
from langchain.memory import MomentoChatMessageHistory, ConversationBufferMemory
from langchain.retrievers import AmazonKendraRetriever
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
# 今回は説明を割愛しますが、OpenAIやmomentoなどのAPIキーは環境変数を利用しています。
load_dotenv()
logger = logging.getLogger(__name__)
def handler(event, context):
# ※実際には、フロントからbodyで受け取ります。
index_id = "{{ kendraのindexID }}"
human_input = "{{ ユーザーの入力値 }}"
session_id = "{{ 会話履歴のためのセッションID }}"
# llmモデル(OpenAI)
llm = ChatOpenAI(
model_name=os.environ["OPENAI_API_MODEL"],
temperature=float(os.environ["OPENAI_API_TEMPERATURE"]),
)
# kendraからドキュメント参照
## 今回のメイン!!
retriever = initialize_kendraindex(index_id)
# 会話履歴(momento cacheを使用 ※今回は説明割愛)
history = MomentoChatMessageHistory.from_client_params(
session_id,
os.environ["MOMENTO_CACHE"],
timedelta(hours=int(os.environ["MOMENTO_TTL"])),
)
memory = ConversationBufferMemory(
memory_key="chat_history",
chat_memory=history,
input_key="question",
output_key="answer",
return_messages=True,
)
# 回答生成
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
return_source_documents=True,
)
res = qa({"question": human_input})
return {
"statusCode": 200,
"body": json.dumps(res["answer"])
}
# 他アカウントKendraに接続するためのsts
# clientプロパティを与え、LangChainのAmazonKendraRetorieverモデル使用
def initialize_kendraindex(index_id):
# kendra-account-roleの一時セッションを付与
sts_connection = boto3.client('sts')
kendra_account = sts_connection.assume_role(
RoleArn = os.environ["ROLE_ARN"], # 環境変数より
RoleSessionName ="cross_acct_lambda",
)
ACCESS_KEY = kendra_account['Credentials']['AccessKeyId']
SECRET_KEY = kendra_account['Credentials']['SecretAccessKey']
SESSION_TOKEN = kendra_account['Credentials']['SessionToken']
client = boto3.client('kendra',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
aws_session_token=SESSION_TOKEN,
)
# kendraはデフォルトが英語なので、言語設定必須
attribute_filter = {"EqualsTo": {"Key": "_language_code","Value": {"StringValue": "ja"}}}
# langchainのAmazonKendraRetorieverモデルにclientオプションを設定
retriever = AmazonKendraRetriever(
client=client,
index_id=index_id,
attribute_filter=attribute_filter,
)
return retriever
おわりに
LangChainを利用して、他アカウントのKendraに接続する方法の紹介でした。
やり方としては、汎用的なSTSを利用した他アカウントサービスへのアクセスと同じ手順で接続が可能です。
LangChainのAmazonKendraRetrieverクラスを利用するときにclientプロパティが用意されているので、ロールの設定さえ間違っていなければすんなり接続することができました。
LLMアプリは各社の社内ルールを読み込ませるなどしてこれからますます流行るでしょうね。
私もその波に乗って取り組み始めたのですが、やはり体系的にまとめ止められている書籍のチカラは大きかったです。
まずは、この書籍通りのSlackアプリを作成して、さまざまなカスタマイズを行いました。
- AWS CDKによる構築
- Amzon Kendraへの参照ドキュメント保存と利用
- LLMとして、Amazon Bedrockからtitanモデルやclaude2モデルの利用
- 参照ドキュメントをベクトル化して、momento vectore index(MVI)への保存と利用
アプリの完成度としてはまだまだですが、さらに改良して業界・社内特化LLMアプリ開発頑張ります。

コメント